JavaScript の並列処理機能を味見してみる
この記事は “A Taste of JavaScript’s New Parallel Primitives” の抄訳です。
まとめ:複数の Worker と共有メモリを利用して、本当の意味で並列アルゴリズムの JavaScript 実装を可能にするために、JavaScript の基本機能を拡張しようとしています。
複数コアを用いた計算
JavaScript (JS) は成熟しました。モダンな Web ページのほとんど全てで、大量の JavaScript が利用され、それらが動作するのは当たり前のことになっています。また JS の適用領域も拡大しています:クライアントサイドでは、Facebook や Lightroom が行っているように画像処理が JavaScript で実装されていますし、Google Docs のようなブラウザで動作するオフィススイートも JS で実装されています。PDF ビューワ(pdf.js)のような Firefox のコンポーネントや言語分類器も JS で実装されるようになっています。それらのうちの幾つかは、C++ コンパイラによって出力される単純化された JavaScript サブセット、asm.js を利用しています。例えば C++ で書かれているゲームエンジンも JS にリコンパイルされ、asm.js のプログラムとしてブラウザ上で動作させられます。
これらに代表される JS の適用範囲の拡大は、パフォーマンスの驚異的な改善によって可能となりました。それは JS エンジンに実装された Just-in-Time(JIT) コンパイラや、より高速な CPU によってもたらされました。
しかし、JIT による実行速度向上のスピードは低下しつつあります。また CPU 速度の改善はほとんど頭打ちになっています。CPU の高速化に代わる手法として利用されているのは、複数の CPU(実際は CPU のコア)の利用です。これは携帯電話からデスクトップにいたるまで広く利用され、ローエンドの環境を除けば、最低でも 2 つ以上の CPU が利用できるようになっています。このような状況でプログラマがプログラムの性能を向上させたいなら、複数のコアの並列利用を選択するでしょう。これは Java、Swift、C#、C++ のようなマルチスレッドプログラミングが可能な言語で書かれたネイティブアプリの話ではありません。Web Worker と、その遅いメッセージパッシング機構、そしてデータコピーの回避手段がほとんどないという、複数の CPU を利用するには極めて制限された機能しか持たない JavaScript での話です。
つまりは JS には問題があるのです:Web 上の JS アプリケーションが、ネイティブに代わる有力な選択肢であり続けるためには、JS を複数 CPU の上で動作させられるような機能を JS に持たせなければなりません。
JS の並列計算:共有メモリ、不可分性、Web Worker
これまでの 1 年程度、Mozilla の JS チームは標準化活動を主導して、並列計算を可能にする機能を JS に加えてつづけてきました。他のブラウザベンダの協力を得て、私たちの提案は JS の標準化プロセスへと進みました。Mozilla の JS エンジンになされたプロトタイプ実装は、並列計算を可能にする機能に関して情報を得るのに役立ちます。また Firefox のいくつかのバージョンでは利用可能です。ここではそれらを利用した実験をおこなっていゆきます。
Extensible Web の精神に基づいて、可能なかぎりプログラムを書かずに利用できる低水準な機能を用意することで、複数の CPU を利用可能にすることを選択しました。用意されたのは、新しい共有メモリ型、共有メモリ上のオブジェクトに対する不可分操作、そして共有メモリ上のオブジェクトを標準的な Web Worker に受け渡す方法です。これらの考えは目新しいものではありません。これらの高レベルな背景と歴史に関しては、Dave Herman のブログポストを参照すると良いでしょう。
SharedArrayBuffer と呼ばれる新しい共有メモリ型は、ArrayBuffer とよく似ています。大きな違いは、SharedArrayBuffer として表現されているメモリは、複数のエージェントによって同時に参照されうる点です(ここでのエージェントとは、Web ページのメインプログラムや、Web Worker のことを指します)。SharedArrayBuffer は、あるエージェントから他のエージェントへと postMessage を通じて受け渡されることで共有されます:
let sab = new SharedArrayBuffer(1024)
let w = new Worker("...")
w.postMessage(sab, [sab]) // Transfer the buffer
Worker は、メッセージから SharedArrayBuffer を取得します:
let mem;
onmessage = function (ev) { mem = ev.data; }
上記のプログラムにより、メインプログラムと Worker とが同じメモリを参照するようになります。この状況を図示すると以下のようになります:
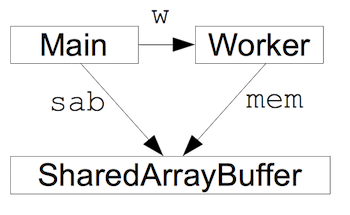
共有された SharedArrayBuffer に対して TypedArray を作り、そのビューに対して配列操作を行うことで、共有メモリ領域に対するデータの読み書きが可能になります。操作例は以下のようになります:
let ia = new Int32Array(mem); ia[0] = 37;
これでメインプログラムは、Worker によって書き込まれたデータを参照できるようになります。上記の例では、Worker の書き込みが終了していれば、37 を得られます。
この「Worker がデータを書き終わるまで待つ」というのは、メインプログラムにとっては実に難しい問題です。複数のエージェントが同じ領域に対して調整することなく読み書きを行うとすると、その結果は悲惨なことになるでしょう。新しく追加した不可分操作によって、操作が割り込みによって中断することなく、予期した順番で処理されるようになり、上述のような協調動作が可能になります。この不可分操作は、新しく追加されたトップレベルオブジェクトの Atomics の静的メソッドとして実現されています。
速度と応答性
Web の性能に関して、複数コア計算によって向上が見込まれるものには 2 つあります。それは計算速度と応答性です。前者は単位時間当たりの仕事量であり、後者は計算中のブラウザに対してユーザが可能な操作の範囲です。
仕事を複数の Worker に割り振り、並行に実行すると速度を向上させられます:1 つの計算を 4 つに分割し、それぞれを 4 つの Worker に割り当て、それぞれの Worker に 1 つずつコアを占有させることができたら、計算が 4 倍速くなることが期待されます。また仕事をメインプログラムから Worker へと移動させることで、応答性を向上させられます。これにより計算途中であっても、UI イベントに対してメインプログラムが応答できるようになります。
共有メモリは 2 つの理由から、並列計算の基本要素となりました。データコピーのコストを削減できることが、1 つ目の理由です。描画を複数の Worker に任せていて、その結果をメインプログラムから表示しなくてはならないといった場合、描画されたシーンはメインプログラムに対してコピーされます。このコピーの分だけ描画時間が増加し、メインプログラムの応答性は低下します。処理の調停コストが低いことが、そして postMessage と比較すると相当低いことが、2 つめの理由です。通信に必要な時間と、エージェントが処理をしないで待っている時間を短縮できます。
良いことだけでなく、悪いこともある
複数の CPU コアを利用することが、簡単でない場合もあります。シングルコアを仮定して作成されたプログラムを複数コアで動作させる場合、大きな変更を余儀なくされる場合がとても多くあります。また変更後のプログラムが正しく動作していることを検証することも難しなります。また Worker 間の調整が頻繁に必要になるようなプログラムは、複数コア利用による計算スピードの向上は難しくなります。すべてのプログラムが並列計算の恩恵を被れるわけではありません。
付け加えるなら、並列プログラムには新しい種類のバグが発生します。プログラムのミスから 2 つの Worker が、お互いの仕事が終わるのを待ってしまった場合、それ以上プログラムが進まなくなります。このような状態をデッドロックと呼びます。複数の Worker が調整なしに同じメモリセルを読み書きした場合、その結果は正しくないものとなるでしょう。このことをデータ競合と呼びます。データ競合のあるプログラムは不正確で、信頼性に欠けるものとなってしまいます。
利用例
注意:以下のデモを実行するためには、Firefox 46 以降が必要です。また Firefox Nightly を利用していない場合は、about:config で javascript.options.shared_memory を true に設定する必要があります。
複数コアを利用して並列に計算してスピードを向上させるために、どのようなプログラムを書けば良いかを見てゆきましょう。例として単純なマンデルブロー集合のアニメーションを利用します。これはピクセルの値をもとにグリッドを計算し、そのグリッドを拡大率を上げながら canvas に描画します。なおマンデルブロー集合の計算は「驚異的並列」として知られています。つまり簡単に高速化が行える種類の計算なのです。他の例ではこれほど簡単には高速化できないのが通常です。また、ここでは技術的に深入りはしません。詳しくは文末にある関連情報を参照してください。
Firefox で共有メモリ機能が標準で利用できないのは、この機能が JS 標準化団体での議論の途中にあるからです。標準化は、その団体のプロセスに則って行われ、その過程で機能が変更されることもあります。そのような API に依存したコードを書きたくはありません。
並列化されていないマンデルブロー集合
最初に全く並列化されていないマンデルブロー集合の計算を見てみましょう。計算はメインプログラムの一部分として実行され、その結果は直接 canvas に描画されます。なおデモは途中で止められますが、後のフレームほど描画が遅くなって行きます。信頼できる結果をえるなら、最後まで実行してください:並列されていないマンデルブロー集合アニメーション
ソースコードはこちらで参照できます:
並列化されたマンデルブロー集合
並列化されたバージョンでは、ピクセルの計算が共有メモリと Worker を利用して並列に行われます。元のプログラムに対する適用は、概念的にはシンプルです:mandelbrot 関数を Web Worker に移します。そして複数の Web Worker を動かし、それぞれの Worker で出力の横一列の計算を担当します。メインプログラムは canvas への描画を担当します:並列化されたマンデルブロー集合アニメーション
使用するコア数とフレームレート(Frame per Second, FPS)との関係をグラフすると、次のようになります。測定に使用したのは、hyperthreading が有効になったコアを搭載した MacBook Pro late-2013 上の Firefox 46.0 です。

1 コアでは 6.9 FPS でしたが、4 コアでは 25.4 FPS へと、プログラムはほぼ線形に高速化しています。その後は新しいコアではなく、すでにプログラムが動作しているコアでの hyperthread 上でプログラムが動作するようになったため、速度の伸びは緩やかになっています。同じコアで動作する hyperthread は、コア上のいくつかのリソースをきょうゆうします。そのためそれらの間での競合が発生しているのではないかと推定されます。それでも hyperthread を追加するたびに、3・4 FPS 高速になり、Worker 数を 8 にした場合は 39.3 FPS となりました。これはシングルコアに比べて 5.7 倍の高速化を達成しています。
この種類の高速化はとても明らかに良い結果になります。一方、並列化されたバージョンは、そうでないものと比べて極めて複雑なものとなっています。この複雑性は様々なものに起因しています:
- 並列化バージョンを正しく動かすためには、Worker とメインプログラムとを同期させる必要があります:メインプログラムは各 Worker に何を計算するべきか伝えなくてはなりません。また各 Worker はメインプログラムに、計算結果をいつ描画するべきかを伝える必要があります。どちらの場合も、
postMessageを利用してデータが渡されますが、通常は共有メモリを通じて渡したほうが良い(つまり高速)です。正しく、効率的にこれを行うは極めて複雑です - 性能を向上させるためには、各 Worker に対して計算を分割し、ロードバランスを行って効率的に Worker を利用するための戦略が必要です。その結果、例として利用したプログラムでは、出力される画像は Worker の数よりもずっと細かく分割されています
- 共有メモリが整数値のフラットな配列であることも、複雑さを増す要因となっています。共有メモリ上の複雑なデータ構造を手動で管理しなくてはならないためです
同期について考えてみましょう。新しい Atomics オブジェクトは、wait と wake の 2 つのメソッドを持っています。どちらも Worker 間でシグナルを送るために利用できます:ある Worker は Atomics.wait を呼ぶことで、シグナルが送られてくるのを待ち受けます。そして他の Worker は Atomics.wake を呼んでシグナルを送れます。これらは柔軟だが低水準の要素です。同期を実現するためには、Atomics.load や Atomics.store、Atomics.compareExchange といった、共有メモリ中の値を読み書きするための機能が必要となるでしょう。
また Web ページのメインスレッドは Atomics.wait を呼ぶことができないことも、複雑さに拍車をかけています。これはメインスレッドを block してしまうのは良くないためですが、Worker 間は Atomics.wait と Atomics.wake を利用して通信を行っているのにも関わらず、メインスレッドを起こすためには postMessage を利用してイベントを送出しなくてはなりません。
これらの機能を試そうと考えているなら、Firefox 46 と Firefox 47 では wait と wake のことを futexWait、futexWake と呼んでいることを知らなくてはいけません。詳しくは MDN の Atomics のページを参照してください。
複雑性の大部分を隠蔽するような良いライブラリをつくることは可能です。またプログラム、通常はプログラムの重要な部分、を複数のコア上で動作させて性能が非常に向上するなら、複雑になっても並列化する意味はあります。それでも並列化は性能を向上させる特効薬ではありません。
上記のディスクレーマーを踏まえた上で、下記の並列化バージョンのコードを参照してください:
より詳しくは
利用可能な API に関しては、提案されている仕様を参照してください。大部分は安定しています。またこの提案を収めた GitHub レポジトリ上での議論も有用です。
また Mozilla Developer Network (MDN) にも SharedArrayBuffer と Atomics に関する文書があります。
Lars T Hansen について
Mozilla の JavaScript コンパイラエンジニア。以前は Adobe で ActionsScript3 の、Opera で JavaScript とブラウザ開発に携わる。
Web サイト:https://github.com/lars-t-hansen